
Datenjournalismus

Heutzutage können Big Data Projekte richtig groß werden. Rund um Flugzeugtriebwerke und deren Wartung entstehen besonders große Datenmengen und Projekte. Um solche Datenmengen zu speichern und auszuwerten, benötigt man Datalakes und leistungsfähige Werkzeuge des maschinellen Lernens.
Industrie 4.0 – Umsetzungshindernisse
Viele Unternehmen haben das Potential der Industrie 4.0 verstanden, doch nicht alle implementieren bereits die passenden Szenerien. Nach Meinung der angefügten Studie sind hierfür auch Lücken in der Software für das Verarbeiten kontinuierlicher Datenströme verantwortlich.
Typische Big Data Projekte
Heutzutage können Big Data Projekte richtig groß werden. Rund um Flugzeugtriebwerke und deren Wartung entstehen besonders große Datenmengen und Projekte. Um solche Datenmengen zu speichern und auszuwerten, benötigt man Datalakes und leistungsfähige Werkzeuge des maschinellen Lernens.
Onlinekurse Machine Learning – Eine Empfehlung
Heute war in den Nachrichten zum Digitalgipfel zu hören, dass Deutschland in künstlicher Intelligenz führend werden soll. Derzeit liegen die USA, und auch China sehr weit vorne. Hierzu passen die heutigen Lernempfehlungen.
Installation von Kubernetes auf einem Raspberry Pi Cluster

Kubernetes wird in Rechenzentren bei Cloudanbietern eingesetzt, um dort containerisierte Anwendungen zu orchestrieren.
Ein beliebtes Raspberry PI Projekt ist die Installation eines solchen Clusters auf diesen kleinen Rechnern, z.B. um damit die Funktionsweise zu erlernen ode zu testen.
Ich habe mir ein solches Cluster aufgebaut, und will es heute in groben Zügen vorstellen.
Digital Twins

Digital Twins (digitale Zwillinge) sind digitale Abbilder realer Maschinen oder Anlagen, und ermöglichen den fehlerlosen Betrieb dieser Anlage. Möglich wird ein solches digitales Abbild durch das Dreigespann maschinelles Lernen, Internet of Things und Big Data.
Lese- und Lernempfehlungen Data Science
Inzwischen dürfte selbst den größten Zweiflern klar geworden sein, daß sich mit der künstlichen Intelligenz viel ändern wird. Die Firma von morgen ist intelligent.
Heute möchte ich Ihnen Lernquellen vorstellen, die sich mit dem großen Thema der Data Science und des Deep Learning befassen.
Fünf zentrale Websites zum Thema Visualisierung von Daten
Letzte Woche habe ich über Data-Lakes geschrieben. Richtig interessant werden diese großen Datenspeicher aber erst, wenn man die vielen Daten auch visualisieren kann. Hierfür benötigt man drei Dinge: Inspiration, Frameworks und Designtechniken.
Die Quellen, die ich in der Anlage zum Artikel aufgeführt habe, liefern genau das.
Erfolgreiche Data Lake Projekte
Datalakes sind wichtige Vorraussetzungen für Projekte im Bereich des maschinellen Lernens oder den data sciences. Daher werden solche Lösungen vermehrt in den Betrieben eingesetzt.
Es gibt hierbei nicht „die“ Architektur, aber sehr wohl existieren Vorgehensweisen, die sich bewährt haben. Es fragt sich, wie ein Datalakeprojekt strukturiert sein sollte, um erfolgreich zu sein.
Big Data Visualisierung – Ein offener Framework von Uber
Die Firma Uber wird zwar in Europa als Taxiunternehmen, und nicht als die Visualisierungsfirma eingestuft, die sie gerne sein würde, trotzdem hat sie eine Visualisierungslösung veröffentlicht, die sehr gut aussieht.
Diese Bibliothek schaue ich mir heute kurz an.
Mit einem Quantencomputer experimentieren
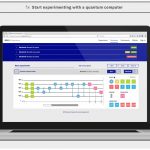
Das maschinelle Lernen, künstliche Intelligenz, oder ganz generell das Lösen von Optimierungsproblemen erfordert Rechnerkapazitäten, und Rechenleistungen, die es heute noch nicht gibt.
Man setzt deshalb viele Hoffnungen in eine neue Art von Rechnern, genannt Quantencomputer. IBM (R) hat einen kostenlosen Service ins Netz gestellt, mit dem man solche Maschinen ausprobieren kann.
Künstliche Intelligenz und Wohlstand in Europa
Der Wettbewerb zwischen den einzelnen Weltregionen in der Zukunftstechnologie der „künstlichen Intelligenz“ ist sehr intensiv.
Das kommt auch daher, weil inzwischen Jedem (und insbesondere den großen Spielern USA, China und Europa) klar geworden ist, daß intelligente Systeme ein riesiges ökonomisches Potential haben.
Welches sind eigentlich die Effekte, und wie kann die Politik dabei helfen, die Technologie zu erschliessen? Hierzu ist ein zukunftsweisender Artikel erschienen.
Cloud Computing: Einführung in Kubernetes und Docker
Kubernetes und Docker liefern wichtige Fähigkeiten, die speziell im Cloud Umfeld benötigt werden aber auch On-Promise eingesetzt werden.
Beide Tools sind besonders bei Entwicklern und im DevOps beliebt, lassen sich aber auch in anderen Bereichen einsetzen. Daher sollte man beide Tools einmal gesehen haben.
Heute gibt es eine Kurzeinführung.
Kontrolle von Maschinenintelligenz und Bias
In einer Welt, in der sich zunehmend intelligente Software verbreitet, gewinnt eine zuverlässige Qualitätssicherung der Algorithmen an Bedeutung.
Die Frage ist, wie man qualitätssichernde Prozesse sinnvoll in der Organisation verankert.
Machine Learning – Empfehlungen für Onlinekurse
Verfahren der Artificial Intelligence, das Machine Learning und das mathematisch-statistische Rechnen finden nach wie vor rasant Verbreitung in der IT.
Wie Sie weiter unten sehen, habe ich Ihnen schon häufiger Empfehlungen für solche Trainings zusammengestellt, an denen ich auch selbst teilnehme.
Derzeit gibt es wieder interessante Lernmöglichkeiten.
Big Data und Daten Journalismus
Daten werden nicht nur in den Unternehmen immer wichtiger, sondern auch im Bereich des Journalismus. Ein Google Newsletter gibt einen guten Überblick – und zeigt auch die Sorgen und Nöte der Journalisten mit der Digitalisierung auf.
Diese sind übrigens ganz ähnlich wie die in den Betrieben.
Big Data Rollen und Teams
Universalgenies sind selten, auch im Bereich der Analytics. Die Entwicklung von Big Data Anwendungen, oder auch Machine Learning Projekte erfordern Mitarbeiterteams, die unterschiedliche Rollen ausfüllen.
Big Data Anwendungen entwickeln und testen

Intelligente Software und Big Data Anwendungen folgen anderen Paradigmen als „normale“ Softwareanwendungen. Daher erfordert ihre Entwicklung eine besondere Vorgehensweise insbesondere im Bereich der Qualitätssicherung.
Machine Learning – Kursempfehlungen
Machine Learning und Data Sciences gehören derzeit zu den heißen Themen in der IT. An beiden Themenbereichen wird schon lange geforscht und gelehrt.
Daher gibt es eine unübersehbar große Menge an guten Materialien, die den Einstieg erleichtern. Ich habe Online Kurse zusammengestellt, die mir geholfen haben, oder, die mir interessant erscheinen.
Machine Learning mit Google Blogs

In der letzten Woche hatte ich Google’s TensorFlow™ als eine der möglichen Bibliotheken für das Machine Learning erwähnt.
Da sehr aktiv in diesem Bereicht, bietet das Unternehmen auf weiteren Gebieten nützliche Inhalte, die sich an Anfänger und Fortgeschrittene in Sachen „Machine Learning“ wenden.
Machine Learning mit TensorFlow

Neulich habe ich über ein Rechnercluster geschrieben, das man einsetzen kann, um darauf Big Data Szenarien auszuprobieren, und Machine Learning Algorithmen zu testen.
TensorFlow™ von Google ist eine der möglichen Bibliotheken für das Machine Learning, die man auf diesem Cluster einsetzen könnte. Daneben ist die TensorFlow Dokumentation eingängig geschrieben, und kann damit auch Einsteigern helfen, die verstehen wollen, wie solche Szenarien aussehen.
Machine Learning in einem eigenen Rechnercluster
Viele Big Data Szenarien verwenden den sogenannten SMACK-Softwarestack (Spark, Mesos, Akka, Cassandra, und Kafka) als Laufzeitumgebung. Dabei handelt es sich um frei verfügbare Software, die normalerweise auf Rechnerclustern in Datenzentren installiert wird, um dort Big Data Anwendungen durchzuführen.
Der kleine Raspberry Pi bietet eine interessante Möglichkeit, um sich ein eigenes Rechnercluster im Wohnzimmer aufbauen zu können.
Mathematische Optimierung mittels OptaPlanner

Im Rahmen des Maschine Learning werden Verfahren, wie neuronale Netze oder Decision Tree Algorithmen eingesetzt, und es werden damit in vielen Fällen gute Erfahrungen gesammelt.
Für manche Problemstellungen bieten sich aber nach wie vor Optimierungsverfahren aus dem Bereich des Operation Research an. OptaPlanner ist eine offene und dabei mächtige Bibliothek.
Machine Learning mit Apache Spark – Einführung

Ich beschäftige mich zur Zeit mit dem Thema „Machine Learning mit Apache Spark“ und habe am Wochenende in der Computerzeitschrift „iX“ einen sehr informativen Artikel hierzu gelesen, und das Beispielprogramm ausprobiert, das darin vorgestellt wurde.



 Ich arbeite seit vielen Jahren in der Softwareentwicklung für Unternehmensanwendungen bei der SAP SE. Dieser Blog ist privat, und die Meinungen sind meine eigenen. Sie sind hier richtig, wenn sie sich für Praxiserfahrungen im Produktmanagement für Investitionsgüter interessieren.
Ich arbeite seit vielen Jahren in der Softwareentwicklung für Unternehmensanwendungen bei der SAP SE. Dieser Blog ist privat, und die Meinungen sind meine eigenen. Sie sind hier richtig, wenn sie sich für Praxiserfahrungen im Produktmanagement für Investitionsgüter interessieren. 